Kilka lat temu, gdy dopiero zaczynałem przygodę z poważnym programowaniem w świecie Javy, nauczyłem się podstaw największego i najważniejszego jej frameworka – Springa. Przeczytałem Spring in Action, zapisałem się na kurs i oczywiście, jak każdy początkujący (i nie tylko) jego użytkownik, rozpalałem wyszukiwarkę Googla i StackOverflow do czerwoności. Sam Spring jest ogromnie rozbudowany i po nauce podstawy (kontenera beanów) poznawałem dalsze jego składowe – SpringMVC, SpringSecurity, SpringData itd. Pamiętam jak zarywałem noce poznając wiedzę tajemną Springa i implementując ją w pisanych na szybko wprawkach. Nie była to zresztą tylko przyjemność ale i wymóg rynku pracy - w świecie backendowej Javy właściwie nie da się Springa nie znać - jest praktycznie wszędzie.
Jak wiadomo Spring powstał jako lekka, przyjemna alternatywa dla EJB (a właściwie całego JEE) które w tamtym czasie było takim potworkiem że ludzie przyjęli Springa z ulgą i otwartymi ramionami. I choć to JEE było półoficjalnym standardem to na palcach jednej ręki mogę zliczyć projekty o których w ogóle słyszałem, że są w nim napisane (przynajmniej na polskim rynku IT). I mimo że JEE stało się z czasem tak samo wygodne jak Spring – sam napisałem na pracę inżynierską taki projekcik – to jednak Spring wygrał rząd dusz programistów. Bo czy słyszeliście o innych poważnych i powszechnie znanych rozwiązaniach IoC backendowej Javy?
Jeszcze kilka lat temu wydawało mi się że Spring jest wspaniałym frameworkiem, bez którego właściwie jesteśmy skazani albo na JEE Jakartę albo jakieś inne, niszowe rozwiązania – no bo jak niby inaczej zrobić poważną aplikację w Javie? Jak zrobić poważne DI? Nie no – bez żartów – bez Springa się nie da… Nie?
Hej - czyżbym właśnie napisał, że jeden z najpopularniejszych języków programowania na świecie jest praktycznie niesamodzielny? Czemu wymaga on czegoś więcej? I nie mam tu na myśli dodatkowych bibliotek dostarczających określone dodatkowe funkcje tylko sam rdzeń aplikacji, sam jej szkielet (frame work). Czemu nie możemy obejść się bez Springa? Czy język programowania i jego biblioteka standardowa nie powinny same w sobie być wystarczającymi szkieletami dla aplikacji? Wydaje mi się że tak! Czemu zatem tak nie jest?
To pytanie nurtowało mnie od kilku lat wraz z rosnącą irytacją wynikającą z używania Springa. Coraz wyraźniej czułem, że zarówno z tym frameworkiem jak i całym podejściem do architektury aplikacji backendowej coś jest mocno nie tak. Im dłużej programowałem tym bardziej się w tym utwierdzałem. Ale co konkretnie mi się nie podoba?
Konkretnie to:
To jest cecha nie tylko Springa czy Jakarty lecz właściwie paradygmatu tych rozwiązań. Już kilka lat temu stwierdziłem, że z punktu widzenia programisty używającego tego podejścia program który właśnie piszemy wygląda jak rozsypanka. Zauważyliście to? Jest sobie jakieś ziarno a obok niego inne. Cała masa ziaren - sporo z nich sam napisałem. W jednym ziarnie odwołuję się do innego - a dokładnie do zależności o typie takim jak to inne ziarno. I choć klasa tego drugiego ziarna jest zaraz obok to ja – programista – nie widzę tego wstrzyknięcia. Nie ja to łączę tylko framework a moja aplikacja bez niego jest niedziałającą rozsypanką takich ziaren - jakby demem aplikacji. Muszę zatem wierzyć że zostanie to dobrze połączone. Podczas pisania czy kompilacji nie widzę tego połączenia i tak naprawdę nie mam pewności że dane ziarno faktycznie zostanie wstrzyknięte. A wielokrotnie okazywało się że jednak nie zostało - wystarczyło że zapominałem dodać adnotację czy zrobić JavaConfiga. Co prawda dobre IDE podpowiada że czegoś tu brak – sęk w tym że w większości projektów w których pracowałem to podpowiadanie z wielu względów nie działało dobrze. Normą jest że IDE podkreśla mi na czerwono pola w klasie dając do zrozumienia że nie widzi moich zależności jako ziaren Springowych – i prawie zawsze się myli bo jednak to działa. No właśnie - prawie – nigdy nie mam pewności. A wstrzykując kolekcję to już w ogóle zostaje mi czysta wiara że będzie to działać.
Największy jednak problem jest z ziarnami samego Springa. Która konfiguracja i które ustawienia faktycznie są załadowane? Nigdy nie mam 100% pewności co tam się dzieje i do czego tak właściwie służą te dziesiątki propertisów. Czy mogę któreś z nich usunąć? Czy coś wtedy nie zadziała? Muszę sprawdzić. A może dla pewności lepiej tego nie ruszać? Eh...
A zauważyliście jak w praktyce wygląda testowanie takiego kodu? Żeby przetestować taką klasę muszę nakarmić ją zależnościami. W przypadku testu jednostkowego nad wyraz często kończy się to mockozą totalną. No bo przecież nie będę ręcznie tworzyć całego drzewa zależności dla jednego testu, prawda? Mocki pozwolą mi przetestować daną klasę sprawdzając dokładnie jak używała ona swoich zależności i jak reagowała na różne dane od nich – i to jest dobre – ale z drugiej strony będą to testy oderwane od rzeczywistości. Przypadki testowe mogą mieć niewiele wspólnego z tym co ta klasa rzeczywiście robi. Nawet jeżeli chciałbym zamockować część zależności to najczęściej mockuję większość lub wszystkie. Rozwiązaniem tego problemu jest test z podniesionym kontekstem aplikacji. Sęk w tym że takie testy uruchamia się dość rzadko. Czemu? Bo są wolne. A wolne są bo stawianie kontekstu trwa długo. Ale o tym później.
Oczywiście nie chodzi mi tutaj o krytykę odwrócenia sterowania (IoC) – to jest moim zdaniem ze wszech miar słuszne – tylko o to konkretne rozwiązanie. Ziarna powinny dostawać swoje zależności z zewnątrz. Marzy mi się jednak takie DI które nie zakryje tego pod tak dużą zasłoną niepewności. Takie, gdzie będę mógł łatwo to zobaczyć i zweryfikować bo nie będzie to ukryte głęboko w trzewiach Behemota. Innymi słowy – proste, czytelne, łatwo i szybko weryfikowalne, oczywiste, naoczne, statycznie typowane i walidowane podczas kompilacji.
No i czy DI musi być zapewniane przez dodatkowy framework? Moim
zdaniem
jest to tak ważna, inherentna i podstawowa kwestia że wręcz nie powinno
tak być!
Zaglądaliście kiedyś do wnętrzności Springa? Mogę bez
strachu o swoje oszczędności postawić piwo każdemu z moich znajomych
kto dobrze je poznał. A właściwie to czy powinniśmy je poznawać? Czy
nie powinno być tak, że to po prostu działa? Moim zdaniem powinno!
Czemu więc tyle
razy na rozmowach o pracę słyszałem pytania o szczegóły implementacyjne
tego Behemota? Ano dlatego że im dłużej się tego używa tym bardziej się
wie że nie jest z tym tak łatwo.
Spring jest bardzo skomplikowany a że stanowi rdzeń aplikacji na nim
opartych to przenosi on to skomplikowanie na nie. W przypadku prostych
aplikacji nie jest to tak widoczne ale oprogramowanie ma taką cechę że
przypomina ogród i bardzo łatwo
się rozrasta. Praktycznie przy każdej springowej aplikacji przy której
pracowałem widziałem jakieś sztuczki, przerośnięte konfiguracje i
niestandardowe podejścia. Najbardziej pokręcone są chyba rozwiązania
SpringSecurity - elementu
który powinien być właśnie najbardziej oczywisty i godny zaufania. A w
czasach przed SpringBootem (nie tak dawnych przecież) wyglądało to
jeszcze gorzej. Dodajmy jeszcze do tego głęboką refleksję i łamanie nią
kodu by otrzymać spaghetti po którym można dostać ostrej niestrawności.
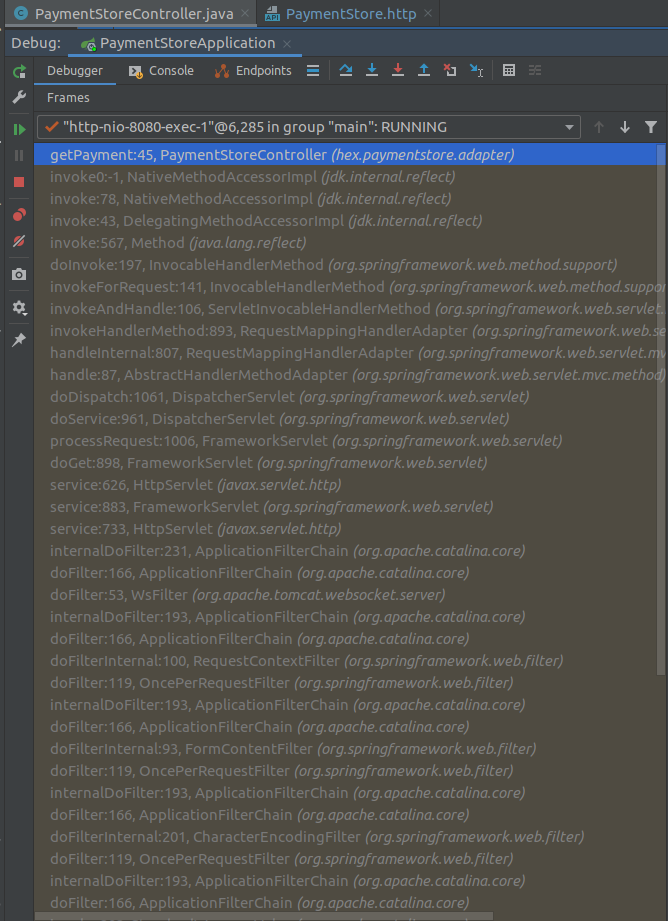
A może kojarzycie coś takiego:
Jest to migawka stosu wywołań w kontrolerze bardzo
prostej
aplikacji. I tak - jest to ucięte jak widać po pasku przewijania.
Czy tylko mi się wydaje że jest tego za dużo? Gdyby
to jeszcze dotyczyło tylko wywołań serwera ale takie coś widzę zawsze
kiedy podglądam komunikację ziaren. Widzę to w logach
wyjątków. Widzę to wszędzie. Czy to jest normalne?
Keep It Simple, Stupid!
Z tym przekomplikowaniem wiąże się też problem kiepskiej wydajności. Aplikacja z przykładu wyżej jest arcyprosta. Właściwie jest to demo napisane pod proces rekrutacyjny do pewnej firmy (i tak - przyjęli mnie po tym :) ). Jest ona napisana w całkiem świeżym SpringBoot i podnosi się na moim laptopie (i7-7700HQ) około 2 sekundy. Niby mało ale aplikacja tej skali powinna wstawać wielokrotnie szybciej. Prawdziwe aplikacje biznesowe na Springu wstają czasami tak długo że można sobie nawet zaparzyć herbatę w międzyczasie ale przecież nie mamy lat siedemdziesiątych by tak się miało dziać.
Kolejnym problemem - o którym pisałem wyżej - jest to że testy integracyjne uruchamiają się tak długo że osobiście znam ludzi którzy ich nie puszczają podczas implementacji. No bo komu by się chciało tracić tyle czasu? :) A na koniec okazuje się że połowa ficzera pisanego kilka dni jest do przeróbki.
Warto też sobie uświadomić jak absurdalnie wygląda podnoszenie aplikacji Springowej. W czasach przed SpringBootem wyglądało to w wielkim uproszczeniu tak: aplikacja Springowa deployowana jest na kontenerze serwletów gdzie na podstawie deskryptora wdrożenia (pamiętacie jeszcze takie coś?) uruchamiany zostawał springowy DispatcherServlet (tak, tak - pozostałość po JEE) który to podnosi kontekst aplikacji i zaczyna nasłuch. Na SpringBoot jest jeszcze ciekawiej bo zamiast deployować to na zewnętrznym kontenerze to przy starcie apki uruchamiany jest wbudowany w aplikację kontener (domyślnie Tomcat). Ileż absurdalnie niepotrzebnych warstw!
Oprócz argumentu wygody programisty jest jeszcze jeden o którym
będziemy myśleć kiedy przyjdzie nam płacić za hosting :)
Znacie takie sformułowanie jak magia w programowaniu? Coś się dzieje automagicznie - czyli jakoś a my nie wiemy jak. Kiedyś mi to imponowało i sam chciałem zostać czarodziejem. Zmieniłem jednak zdanie po miriadach napisanych linii kodu. Magia jest fajna jak działa ale jak coś przestaje działać to nagle się okazuje że mam ochotę takich czarodziejów spalić na stosie. Oczywiście nie mam tu na myśli używania abstrakcji, bibliotek czy wydzielania odpowiedzialności. To są właśnie te rzeczy których inżynierowie powinni używać. Jednak Spring i jemu podobne narzędzia robią to źle. Programowanie deklaratywne połączone z łamaniem kodu głęboką refleksją oraz springową rozsypanką, gdzie nigdy nie mam pewności czy coś zadziała, sprawia że zamiast programować z przyjemnością i skupić się na logice biznesowej to raczej czuję się jak inżynier przy szamanie - sam nie wiem czy powinienem patrzeć na niego z podziwem czy z zażenowaniem (choć z biegiem czasu coraz częściej patrzę w ten drugi sposób). Czekam już tylko na aplikacje które będą pisane tylko jako springowe konfiguracje w yamlu.
Czyż nie tęsknicie za czasami, gdy programiści byli programistami i sami pisali swoje aplikacje?
Na koniec jeszcze jedna refleksja. Pamiętacie jeszcze filozofię UNIXa? Ja wiem że często się już tego nie stosuje, że jest sporo dobrego softu który zdecydowanie nie jest mały i jednozadaniowy i że tak jak we wszystkim w życiu trzeba znaleźć złoty, wygodny środek. Filozofia Springa jednak to już przegięcie. Bardziej niż powiew wiosny przypomina on już gradobicie. "Skoro mamy już Springa to użyjmy jeszcze SpringXxx - dostajemy to przecież prawie za darmo no i chyba jest spoko, nie?" Czy czegoś Wam to nie przypomina?
Jeden, by wszystkimi
rządzić, jeden, by
wszystkie odnaleźć,
Jeden, by wszystkie zgromadzić i w ciemności związać.
Kilka lat temu zacząłem się zastanawiać jak można ominąć
te problemy. Szukałem sensownej alternatywy która nie powieliłaby tych
minusów a jednocześnie dawałaby wygodę tworzenia wydajnych,
skalowalnych, testowalnych i rozwijalnych aplikacji.
Pamiętam jak trzy lata temu będąc na Confiturze zobaczyłem to
wystąpienie na temat alternatyw dla Springa. Pamiętam też, że
zrobiło to
na mnie bardzo słabe wrażenie - zamiast pokazać jakieś ciekawe i
sensowne alternatywy utwierdziło mnie w przekonaniu, że takie
praktycznie nie istnieją. Jednak kilka miesięcy później zobaczyłem
wystąpienie
Jarosława Ratajskiego które doskonale wpasowało się w moje
przemyślenia i utwierdziło mnie w przekonaniu że sam język ma wszystko
to czego mi potrzeba. W wystąpieniu tym nie znalazłem niestety
konkretnych propozycji. Spróbowałem więc
samemu napisać bardzo prosty framework DI oparty na mirokontenerze.
Rozwiązywał on wiele omówionych wyżej problemów ale wciąż było to
rozwiązanie mało doskonałe. Zacząłem więc zastanawiać się jak bez
żadnego frameworka zrobić dobre DI tak, by nie było to karkołomne.
Wyznaczyłem sobie kilka
założeń. Ma to być:
Około półtora roku temu wpadłem na pomysł jak to zrobić. Nadejście zarazy koronawirusa w 2020 roku i związane z tym obostrzenia dały mi czas i impuls by spróbować napisać jakąś aplikację opartą na tym pomyśle.
W tym też czasie poznałem i zakochałem się w nowym języku - Kotlinie. Jest tym czego potrzebuję od języka i tym czym Scala powinna być od początku a nigdy się nie stała. Od tego czasu piszę prywatnie na JVM już tylko w Kotlinie - i próbuję swoich sił w Kotlinie poza JVM. Język ten i cały jego ekosystem przynosi wiele ciekawych roziązań. Sprawia też że coś, co w Javie byłoby karkołomne i niewygodne, w nim jest jak najbardziej wygodne, eleganckie i proste. Pozwala mi skupić się na meritum zamiast bohatersko zmagać się z rzeczami, którymi w ogóle nie powinienem się zajmować. Wspomniany pomysł na rozwiązanie jest oparty właśnie na Kotlinie i dzięki temu językowi możliwe jest spełnienie założeń prostoty i wygody.
Rozwiązanie na które wpadłem jest wręcz banalnie proste lecz wydaje mi się że spełnia powyższe założenia. Opiera się ono na kotlinowych objectach oraz swoistym wzorcu projektowym który można nazwać Lazy Properties Application Context.
Znacie zapewne wzorzec projektowy Singleton - wszyscy programiści
się go uczą a prawie nikt nie wykorzystuje. Nie oznacza to jednak że
nie potrzebujemy
klas z jedną tylko instancją, dostajemy to jednak od frameworka, który
to on dba o ich tworzenie. Od kilku lat czułem że coś tu jest nie tak.
Instancje takie są często niemożliwe do stworzenia bez głębokiej
refleksji albo są to zwykłe klasy
tworzone
konstruktorem. W tym pierwszym przypadku jeszcze bardziej uzależniamy
się od frameworka a w drugim całkowicie odchodzimy od wzorca Singleton.
Rozwiązaniem idealnym byłoby gdyby sam język wspierał ten wzorzec i jak
się okazuje dokładnie tym są kotlinowe objecty. Postanowiłem użyć ich
jako podstawy dla ziaren aplikacji.
Nie zawsze jednak chcemy odnosić się do danego ziarna bezpośrednio lecz potrzebujemy schować go za interfejsem. W architekturze portów i adapterów domena w ogóle nie powinna znać konkretnej implementacji adaptera. Tutaj z pomocą przychodzi kontekst aplikacji. Kontekst oparty na kontenerze jest jednak tym czego właśnie chciałem uniknąć. Rozwiązanie nasunęło się więc samo - potrzebuję po prostu klasy kontekstowej gdzie ziarna będą jej polami (w świecie kotlinowym mówi się o properties). Singletony mogą pobierać swoje zależności z takiego właśnie źródła zamiast konstruktora. Rozwiązanie wręcz banalne. Żeby nie było problemów z ładowaniem ziaren i ich sekwencją zrobiłem je leniwymi - z użyciem kotlinowego lazy. Dodałem do tego bardzo prostą implementację profili i tyle! Ale gadanie jest tanie. Kod wygląda tak:
open class AppContext(args: Array<String>) {
val properties = lazy { AppProperties(args) }
private val profiles = lazy { listOf(DemoProfile).filter { properties.value.profiles.contains(it.name) } }
private fun <T> from(supplier: (Profile) -> T?): T? = profiles.value.firstNotNullOfOrNull(supplier::invoke)
open val postsRepository = lazy { from(Profile::postsRepository) ?: DatabasePostsRepository }
open val databaseConnection = lazy { DriverManager.getConnection(properties.value.dbURL) }
}
private interface Profile {
val name: String
val postsRepository: PostsRepository? get() = null
}
private object DemoProfile : Profile {
override val name = "demo"
override val postsRepository: PostsRepository = DemoPostsRepository
}
Ledwie kilkanaście linii kodu. Każde ziarno w kontekście to jedna linijka kodu - tyle samo ile adnotacja @Component czy wpis w JavaConfig. Ziarna mogą być zależne od profilu bądź nie. Dodatkowo do testów można przygotować osobny kontekst:
object TestContext : AppContext(arrayOf()) {
override val databaseConnection = lazy<Connection> { DriverManager.getConnection("jdbc:sqlite::memory:") }
}
A tak wygląda ładowanie ziaren z kontekstu:
object Controller {
private val repository by appContext.postsRepository
I jest to walidowane podczas kompilacji (oczywiście IDE bez problemu
wszystko podpowiada podczas pisania) i statycznie typowane. Podlega też
pod kotlinowe null safety.
Zastanawiałem się też czy wszystkie ziarna (objecty) powinny być w
kontekście ale stwierdziłem że dam tam tylko te, które rzeczywiście są
zależne od kontekstu uruchomieniowego, są adapterami (w architekturze
portów i adapterów) oraz te które chciałbym mockować w testach. Cała
reszta może być zwykłymi objectami
wywoływanymi bezpośrednio.
Rozwiązanie to załatwia nam kwestię odwrócenia zależności bez użycia
kontenera. A co z funkcjonalnościami które daje nam Spring? Tutaj
stwierdziłem że powinniśmy zastosować zasadę UNIXa. Na rynku jest ogrom
rozwiązań do każdego zapotrzebowania a ich analizą i oceną będę się
zajmować (między innymi) na tym blogu.
No właśnie. Ciekaw byłem jak takie rozwiązanie wypadnie w praktyce
dlatego postanowiłem to połączyć z moim planem stworzenia tego bloga i
napisałem go jako aplikację opartą na tym właśnie pomyśle. Okazało się
że działa to bez problemu i spełnia, moim zdaniem,
wszystkie założenia. Uruchamia się ona błyskawicznie i działa bez
zarzutu. Jako serwera użyłem tam Ktora - najpopularniejszego serwera w świecie
Kotlina. Miałem wobec niego
pewne obawy - jest bowiem już właściwie frameworkiem. Na szczęście
ogranicza się do serwowania i nie wpływa na całość aplikacji; jest
dobrze konfigurowalny i ma świetną dokumentację.
Całość opublikowana
jest na GitHubie tutaj.
Aplikacja ta jest bardzo prosta i będzie się rozwijać razem z tym
blogiem co stanie się najlepszym dla niej sprawdzianem.
Przejrzyjcie
kod i dajcie mi znać co o tym sądzicie :)